With an anxious feeling at this moment, I have decided to write a blog article to relieve that feeling. Again, it is all about summarizing things that I have recently worked on, this time is some caching techniques in Python.
1. General concept
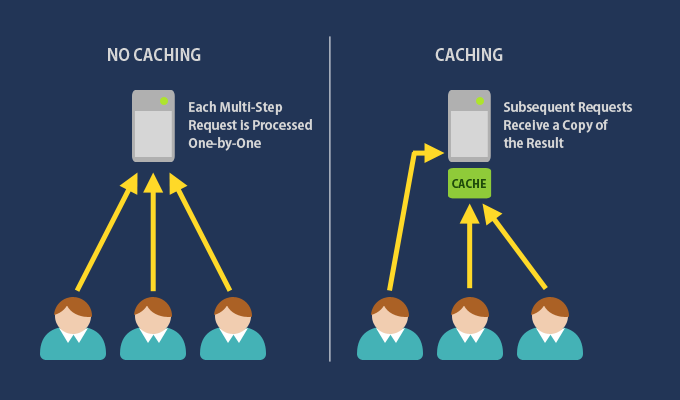
Cache is the concept of storing computed data in a space (RAM, files, …) where it can be accessed at a greater speed. This technique is a savior of many systems, databases, and services having huge traffic daily.
- Increase reading time
- Reduce the workload on servers, databases
- Predictable performance
In one example, it takes 5 seconds for your system to perform action A. In the subsequent requests coming with the same input of action A to produce the same result, should we run A again? The answer is NO, instead of performing that heavy action again, we should store the computed result of the first request somewhere and use that result for the incoming requests having the same input.
It is like when you note down some useful information in the interesting book you are reading. Next time when you want to find that information, finding it in the notebook is greatly faster than skimming the whole book again.
2. When should we cache?
As a software engineer, we should analyze whether caching that specific resource is appropriate or not, it depends on how frequently that resource is written and read (we should be dynamic, that characteristic will create a great engineer).
- If a resource is written more frequently than read, the cons will outweigh the pros because the cache will be modified frequently. In that case, not caching or caching the small portion of that resource are more effective.
- If the task is not intensive and there is no huge traffic, we should not cache to save human resources for other features
- If the operation consumes much time and resources to compute or it is heavily read, caching should be done here
3. What type of cache should we use?
According to Ironistic (2014), there are 4 major types of caching:
- Web Caching (Browser/Proxy/Gateway)
- Memory Caching
- Application/Output Caching (HTML, CSS, JS)
- Distributed Caching
In the scope of this article, we will only focus on the second and last types. After that, I will share some of my experiences with them, which one would be the most beneficial to choose in each case.
a. Memory Caching
A type of cache that saves data in RAM allocated for its own process. This is by far the fastest caching technique because RAM accessing is really fast, but it has some limitations:
- Cached data cannot be shared across processes because each process has its own memory space
- Cannot fully utilize the potential of caching because the output can be computed many times in case multiple processes are running
- If one process stops, its cached data is completely gone
- Hard to scale up because it requires stronger servers (RAM often comes with CPU) which has a greater cost
Use case: Memory caching should be used in standalone applications like a single server, a mobile application, etc.
Python libraries: cachetools, …
b. File Caching
As I mentioned above, memory caching cannot share the memory between processes. Even though file caching is slower due to I/O operations to files stored in a hard disk, it solves all problems that memory caching has.
File caching also has its disadvantages:
- I/O operations to hard disks are much slower than RAM (The statistic is retrieved from “Access time” (n.d.)
- HDD: 5-10 milliseconds
- SSD: 25-100 microseconds
- RAM: 10 nanoseconds
- Cached data cannot be shared between a cluster of nodes when we have multiple nodes running
Use case: If you have only one server and multiple processes running in parallel, this is an effective solution.
Python libraries: Diskcache, (you can code your own, …)
c. Distributed Caching
Distributed caching puts all the caches in RAM but in a different server. This is a preferable approach for big systems because it completely eliminates all disadvantages of other types. Scaling is not a costly problem anymore, it is possible to rent servers having a high volume of RAM with a small CPU computation capacity.
Applications communicate with cache servers using TCP protocol; if all of the instances are put in the same network, the communication speed is not a problem.
Use case: Apply for big systems having multiple nodes running at the same time.
Technologies: Redis, Memcached
4. Eviction Policies
There are several eviction policies that are available in caching libraries or technologies, below are the policies that I know. Note that these will be applied when a cache achieves its maximum allocated volume.
- Least Recently Stored (LRS - Queue): Work like a queue. Whenever a new item is added, the oldest item will be eliminated.
- Least Recently Used (LRU): Each item will maintain its most recent hitting time. Whenever a new item is added, the item having the oldest hitting time will be eliminated.
- Least Frequently Used (LFU): Each item will maintain its counter. Whenever a new item is added, the least used item will be eliminated.
- None: No policy applies, the items will be eliminated only when it expires.
5. Caching Patterns
- Lazy caching: Only requested items will be cached. If one item is used, firstly check it from the cache. If it is not available, use it. If not, the DB query will operate, cache the item, and use it.
- Write-through: The cache is updated in real-time when the database is updated.
There are several more strategies written here, they are Write Behind Caching and Refresh Ahead Caching. I will leave them to you guys to figure out.
6. References
- “Caching Best Practices” (n. d.). AmazonWebServices. https://aws.amazon.com/vi/caching/best-practices/
- Ironistic (2014). Four Major Caching Types and Their Differences. Ironistic. https://www.ironistic.com/insights/four-major-caching-types-and-their-differences/
- Nath. K. (2018). All things caching- use cases, benefits, strategies, choosing a caching technology, exploring some popular products. Medium. https://medium.datadriveninvestor.com/all-things-caching-use-cases-benefits-strategies-choosing-a-caching-technology-exploring-fa6c1f2e93aa