Sau khi đã tìm hiểu về R-CNN, chúng ta hãy cùng đi tìm hiểu về một kiến trúc tối tân hơn R-CNN vào năm 2015, chỉ 1 năm sau sự ra đời của nó, đó chính là Fast R-CNN. Fast R-CNN là một phiên bản hoàn thiện hơn và khắc phục được các hạn chế mà R-CNN còn mắc phải.
Trong bài viết này, chúng ta sẽ tìm hiểu về điểm đặc biệt của Fast R-CNN so với người đàn anh của nó, cách network này giải quyết các vấn đề của R-CNN, đồng thời khám phá sâu hơn về cách network này được huấn luyện.
Kiến trúc
Trong mục này, chúng ta sẽ tập trung vào cách mà Fast R-CNN hoạt động để hiểu được bức tranh toàn cảnh. Sau đó, chúng ta sẽ khai phá sâu hơn về từng component trong network này.
Fast R-CNN đã bỏ lớp SVM mà R-CNN đã sử dụng để xác định đối tượng sau khi chiết xuất đặc trưng, thay vào đó, network này là một model thống nhất, giải quyết việc phân loại và định vị đối tượng. Bằng hướng tiếp cận này, Fast R-CNN đã loại bỏ được 2 trong 3 khuyết điểm của R-CNN, đó chính là:
- Sự phức tạp khi huấn luyện model
- Không gian lưu trữ cho các model SVM
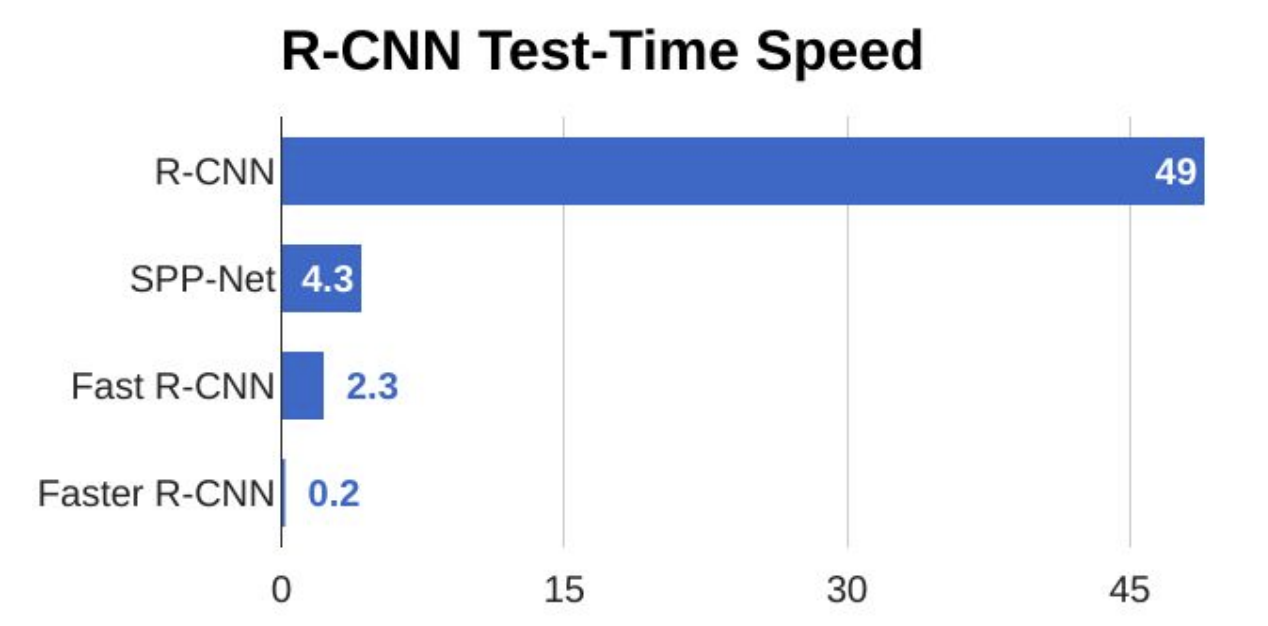
Thêm vào đó, bằng cách tích hợp RoI Pooling Layer, khuyết điểm còn lại là hiệu năng cũng được giảm đi đáng kể. Bạn có thể tham khảo bảng thời gian hiệu năng bên dưới.
Vì đã là một thể thống nhất, chúng ta có thể thoải mái huấn luyện và điều chỉnh các thông số của model, không cần phải quan tâm việc lấy đặc trưng từ CNN và feed vào SVMs nữa.
Model này cũng sử dụng Softmax thay cho one-vs-rest SVMs, nên dung lượng model sẽ giảm đi đáng kể so với R-CNN. Theo một thử nghiệm trong paper, việc sử dụng Softmax trong Fast R-CNN vượt trội hơn 0.1 đến 0.8 mAP point so với SVM. Vậy là tiện cả đôi đường :D.
Vì có khả năng giải quyết được nhiều tác vụ trong cùng một model, có thể đoán chắc rằng kiến trúc của Fast R-CNN sẽ phức tạp hơn so với kiến trúc cũ. Để hiểu rõ hơn về kiến trúc, bạn có thể nhìn hình dưới.
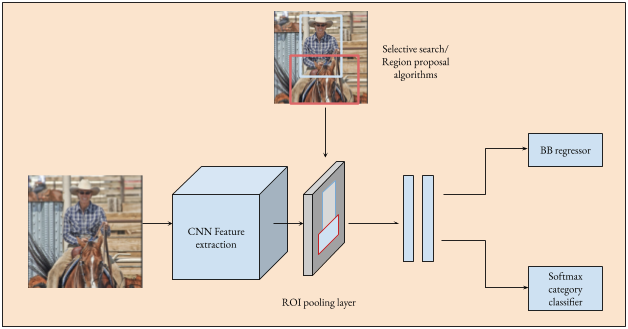
Giả sử chúng ta cần phát hiện $K$ lớp đối tượng.
- Selective search được sử dụng để lấy các RoIs từ ảnh
- CNN chiết xuất tất cả đặc trưng của ảnh thành feature map
- Theo từng RoI, network ánh xạ đến feature map tổng để lấy một feature map trong vùng đó, sau đó cung cấp cho RoI Pooling Layer
- Kết quả từ RoI Pooling Layer là một feature vector và được cung cấp cho fully connected layer, layer này được chia thành 2 nhánh con để thực hiện 2 nhiệm vụ khác nhau, và kết quả là xác suất cho $K$ lớp đối tượng đồng thời vị trí của mỗi đối tượng đó.
Không quá phức tạp nhỉ? Đúng vậy, tuy nhiên để huấn luyện model này, chúng ta cần phải quan tâm đến các thành phần quan trọng như:
- RoI Pooling Layer
- Loss function
- Back propagation
Ở các mục tiếp theo, chúng ta sẽ làm rõ từng phần này.
Lưu ý: Để tránh nhầm lẫn, tôi xin được gọi feature map của CNN là feature map tổng, còn của RoI thì vẫn giữ nguyên là feature map.
RoI Pooling Layer
Như các bạn đã biết, đầu vào cho FCN phải là các dữ liệu có kích thước cố định, tuy nhiên thì các RoI chắc chắn sẽ có nhiều kích thước khác nhau, như kích thước của 2 chú gấu ở hình dưới.

Vì vậy, CNN của chúng ta sẽ gặp rắc rối ở đây, bởi vì thông thường đối với các bài toán phân loại, kích thước hình ảnh sẽ được co giãn thành một giá trị cố định. Do đó, RoI Pooling Layer sẽ được sử dụng để biến đổi các kích thước ngẫu nhiên thành cố định. Đầu tiên, chúng ta cần phải hiểu khái niệm RoI Max Pooling, các bạn có thể tham khảo hình dưới.
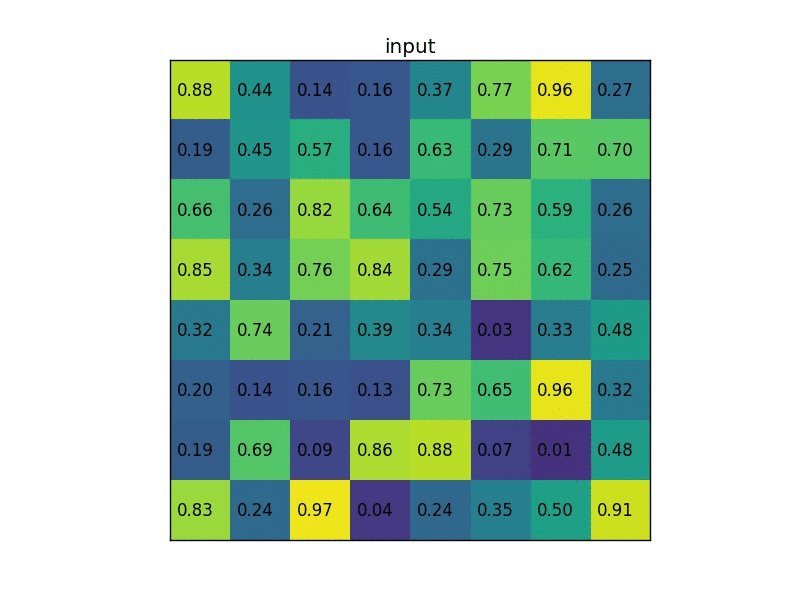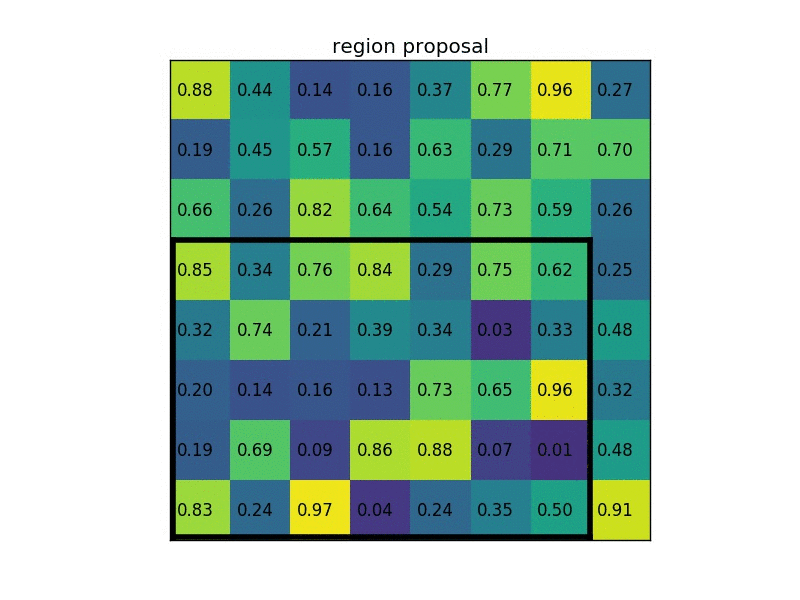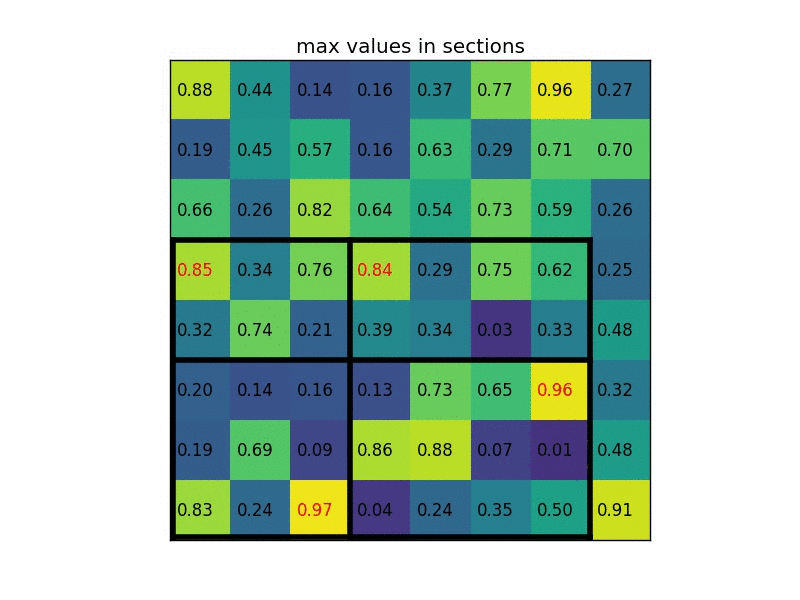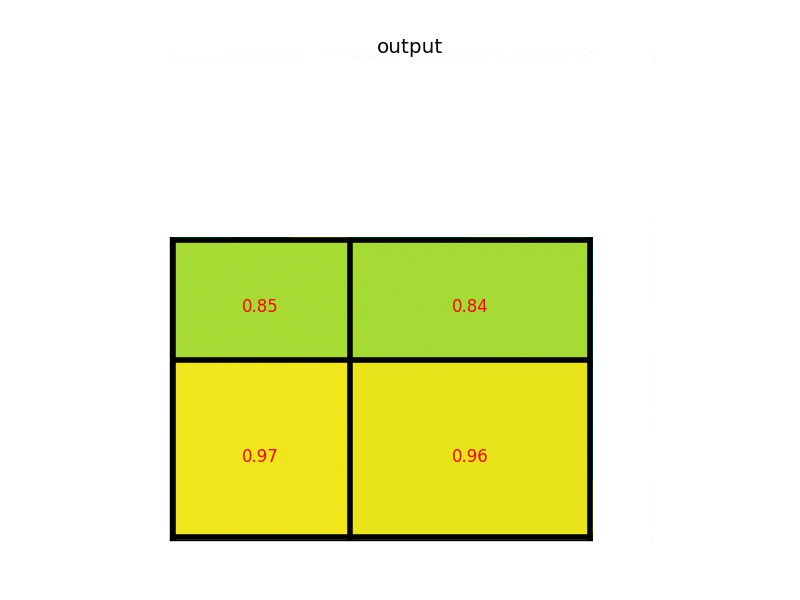
Giả sử, một feature map tổng có size 8x8, tuy nhiên feature map của RoI chỉ có kích thước 5x7, để lấy một feature map mới từ RoI (kích thước 2x2 như trong ảnh), chúng ta cần phải chia kích thước của feature map thành 2x2 phần, mỗi phần sẽ có kích thước tương đối bằng nhau, sau đó lấy giá trị tối đa của từng phần.
Tiếp theo, chúng ta hãy tìm hiểu khái niệm RoI Pooling Layer. Dựa trên nghiên cứu của SPPnets, Fast R-CNN sử dụng khái niệm này để diễn tả một trường hợp đặc biệt của Spatial Pyramid Pooling Layer. Hình bên dưới sẽ mô tả cách layer này hoạt động.
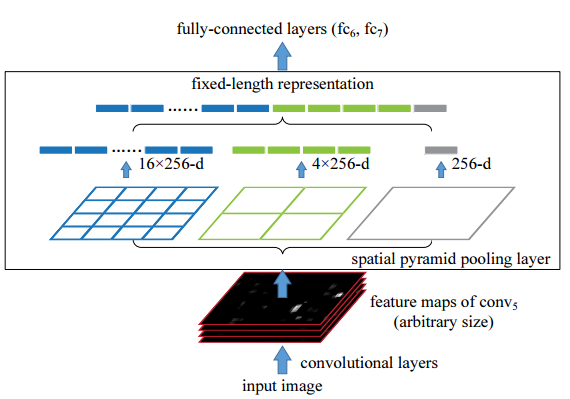
Ở đây, bạn có thể thấy rằng chúng ta đã quy định 3 kích thước: 4x4, 2x2 và 1x1, số lượng này sẽ tuỳ các bạn đặt ra bất kể kích thước của feature map. RoI Pooling Layer sẽ áp dụng RoI Max Pooling cho từng kích thước, sau đó sẽ nối kết quả của từng kích thước lại tạo nên một feature vector có kích thước cố định cho mọi RoI, trong trường hợp này là 21x256. Lưu ý rằng 256 ở đây là số lượng filter cho layer này.
Huấn luyện
Như đã đề cập ở trên, network đã được gom thành một thể thống nhất, việc huấn luyện sẽ trở nên dễ dàng hơn. Vì vậy, Loss function phải trở nên phức tạp hơn để đánh giá độ chính xác của hai nhiệm vụ, từ nhiệm vụ phân loại cho đến xác định bounding box. Đồng thời Back propagation cũng cần phải được cải tiến để phù hợp với RoI Pooling Layer.
Trước tiên, để tìm hiểu việc huấn luyện đa nhiệm vụ như thế nào, thì bạn có thể tham khảo link này, được viết bằng PyTorch.
Khi tìm hiểu về Loss Function và Back propagation, chúng ta cần biết rằng Optimization function của Fast R-CNN là Stochastic Gradient Descent (SGD). Các bạn có thắc mắc rằng nếu nhiều đối tượng trong cùng một ảnh được huấn luyện thì quá trình converge sẽ lâu hơn không? Dựa trên paper, vấn đề này thực tế không xuất hiện, và Fast R-CNN train với ít lần lặp hơn so với R-CNN.
Bây giờ chúng ta sẽ bắt đầu tìm hiểu Loss function và Back propagation nhé.
Loss function
Không như AlexNet sử dụng Cross Entropy loss, Fast R-CNN sử dụng loss function mới trong ngữ cảnh này, đảm bảo rằng loss của kết quả trả về từ nhiệm vụ phân loại và định vị bounding box sẽ là ngang nhau. Dưới đây là công thức của loss function:
\[L(p, u, t^u, v) = L_{cls}(p, u) + \lambda[u \geq 1]L_{loc}(t^u, v)\]Ban đầu chúng ta sẽ nhìn tổng quan loss function này, sau đó sẽ đi sâu vào phân tích từng công thức. Hàm này được cấu thành từ loss của 2 nhánh mà FCN đã chia ra, đó là $ L_{cls} $ (phân loại) và $ L_{loc} $ (định vị).
Nhiệm vụ phân loại (classification)
\[L_{cls}(p, u) = -\log(p_u)\]Ký hiệu:
- $p$: xác suất của K lớp
- $u$: xác suất của ground-truth
Theo như công thức, với loss cho nhiệm vụ phân loại, chúng ta chỉ nhận $\log$ của lớp trùng với ground-truth $u$.
Nhiệm vụ định vị bounding box
\[L_{loc}(t^u, v) = \sum_{i \in \{x, y, w, h\}} smooth_{L_1}(t_i^u - v_i)\]Với:
\[smooth_{L_1}(x) = \begin{cases} 0.5x^2 & \text{if $\lvert x \lvert < 1$} \\ \lvert x \lvert - 0.5 & \text{otherwise} \end{cases}\]Ký hiệu:
- $t_i^u = (t_x^u, t_y^u, t_w^u, t_h^u)$: Bounding box được dự đoán cho ground-truth
- $v$: Ground-truth bounding box
Trước tiên, chúng ta cần phải hiểu rằng nhiệm vụ này là một nhiệm vụ hồi quy (regression). Loss của background bounding box sẽ bị loại bằng $[u \geq 1]$ trong $(1)$, đồng thời loss chỉ dựa trên ground-truth như nhiệm vụ phân loại. Nếu bạn tự hỏi $\lambda$ được sử dụng làm gì, thì bạn khá tinh tế đấy, tham số này là tỉ lệ giữa nhiệm vụ phân loại và nhận diện bounding box, trong paper mặc định $\lambda = 1$.
Lưu ý: Dữ liệu của bounding box cần được scale xuống khoảng $[0, 1]$
Back propagation
Đã hiểu được RoI Pooling Layer rồi, bây giờ chúng ta cũng cần phải hiểu cách gradients từ fully connected layer được truyền qua layer này để cập nhật trọng số của các convolutional layer. Phần này tôi sẽ nói theo cách hiểu của mình dựa trên paper.
Dưới đây là công thức toán học mô tả cách hoạt động của RoI Max Pooling (hiểu forward trước khi nghiên cứu backward):
\[y_{rj} = x_{i^*(r, j)}\]Với
\[i^*(r,j) = \underset{i' \in R(r, j)}{\operatorname{argmax}}x_{i'}\]Ký hiệu:
- $x_i \in \mathbb{R}$: Giá trị đầu vào activation $i$ truyền vào RoI Pooling Layer
- $y_{rj}$: Kết quả của layer $j$ từ RoI thứ $r$
Như đã nói ở trên, đối với mỗi RoI, chúng ta sẽ cần chiết xuất feature vector tương ứng. Dựa theo từng phần, ký hiệu là $ R(r, j) $, của kích thước trong RoI Max Pooling, ta cần tìm vị trí $ i∗(r, j) $ sao cho activation của vị trí này trong vùng $ R(r, j) $ là lớn nhất. Lưu ý rằng tùy theo giá trị của kích thước mà $j$ có thể thay đổi.
Tiếp theo đến phần backward, khi cập nhật gradient, chúng ta chỉ cần quan tâm đến các vị trí $ i = i∗(r, j) $ trong một RoI, các vị trí khác sẽ không có gradient, công thức ở dưới sẽ thể hiện rõ việc này.
\[\frac{\partial L}{\partial x_i} = \sum_{r}\sum_{j}[ i = i∗(r, j)] \frac{\partial L}{\partial y_{rj}}\]Khuyết điểm
Như hình ở trên, khi test thì chỉ mất khoảng 2.3s, nếu so với R-CNN thì mất tận 49s. Tuy nhiên, khuyết điểm của Fast R-CNN nằm ở Selective Search, thuật toán này tốn nhiều thời gian để tạo nên các RoI so với tổng thời gian của network. Vì vậy ở Faster R-CNN, các nhà nghiên cứu đã thay Selective Search bằng Region Proposals Network để học các vùng RoI.
Kết luận
Vậy là chúng ta đã đi xong Fast R-CNN rồi. Trong bài viết sắp tới tôi sẽ nghiên cứu Faster R-CNN, các bạn nhớ theo dõi nhé.