At some points, we encounter some problems that make our applications tremendously slow. It could be the amount of computation is large, or accessing multiple resources at the time, or too many tasks need to process, etc. As the amount of user grows, unexpected problems can happen. In that stressful time, we have to optimize our code line by line and make sure that the physical resources are efficiently used. Not only optimizing the SQL queries like the suggestion from my previous post, but concurrency and parallelism are also the irresistible choices that we should choose.
As you have read in the title, we will discuss the topics related to concurrency and parallelism today. I have had an intention to write about these topics for a long time but procrastinating until now. I hope that you guys can enjoy this post.
 Retrieved from Baeldung
Retrieved from Baeldung
1. Multi-threading
 Retrieved from Toptal
Retrieved from Toptal
a. Example
When we have a large task needs much time to run such as downloading 200 files from S3 to your server per call, and the technology used doesn’t support downloading a whole directory (such as Boto3). The naivest way is retrieving all the files in that directory, loopping through them, then downloading them in order. But that whole process needs to call 200 HTTP requests to S3 subsequently (assuming that 5 seconds/request), so we have to wait over 15 minutes to get all the files. Are there any other approaches to improve this task beside using awscli?
Fortunately, multi-threading can solve this problem quick and easy. Rather than having a main thread waiting 200 times, why don’t we create 200 threads and wait one time?
b. Definition
Multi-threading is the ability to split a big I/O bound task into multiple smaller and independent tasks and handle them concurrently. Threads can run on different CPUs but only one can control the interpreter at a time due to Global Interpreter Clock (GIC), then the context switching mechanism switches to another thread. Therefore, tasks waiting for external events are the appropriate candidate for this kind of processing.
Questions:
Why call it concurrent but only one thread is executed at a time? Once a thread has its turn to execute (context switching is very fast), it runs the instructions then waits for the outcome of an external event. It is called concurrent due to the actions of waiting run in the same time.
What are race conditions in multi-threading? Race conditions occur when multiple threads access the same resource simultaneously. If undesirable events happen like thread A modifies the data while thread B is using it, the result can be unpredictable.
Why do race conditions happen when only one thread executes at a time? Context switching can interupt execution at any point, so the data can be potentially modified by multiple threads.
c. How to use?
Imagine we perform an I/O operation that takes 5s to complete (download a large file on the Internet).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import requests
import time
def download_large_file():
time.sleep(5)
def main():
start_time = time.time()
for i in range(5):
download_large_file()
print("Total time: %.2fs" % (time.time() - start_time))
main()
# Output:
# Total time: 25.00s
Let’s modify things a little bit with threading library supported in Python.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
from threading import Thread
def main():
start_time = time.time()
threads = []
for _ in range(10):
thread = Thread(target=download_large_file)
thread.start()
threads.append(thread)
print("Done creating threads: %.4fs" % (time.time() - start_time))
for thread in threads:
thread.join()
print("Total time: %.4fs" % (time.time() - start_time))
main()
# Output:
# Done creating threads: 0.00s
# Total time: 5.01s
# Remember the time could be even longer due to limited network bandwidth
d. Advantages
- Cut down the waiting time of non-computational tasks.
- Shared memory (multiple threads use the same memory space), so any changes can be utilized in other threads.
- Use physical resource more efficiently.
- Improve system performance.
- Write code in a more structured way.
e. Disadvantages
- Race conditions (This one deserves another post).
- Difficult to debug.
- Too many concurrent threads can result in severely degraded performance.
2. Multi-processing
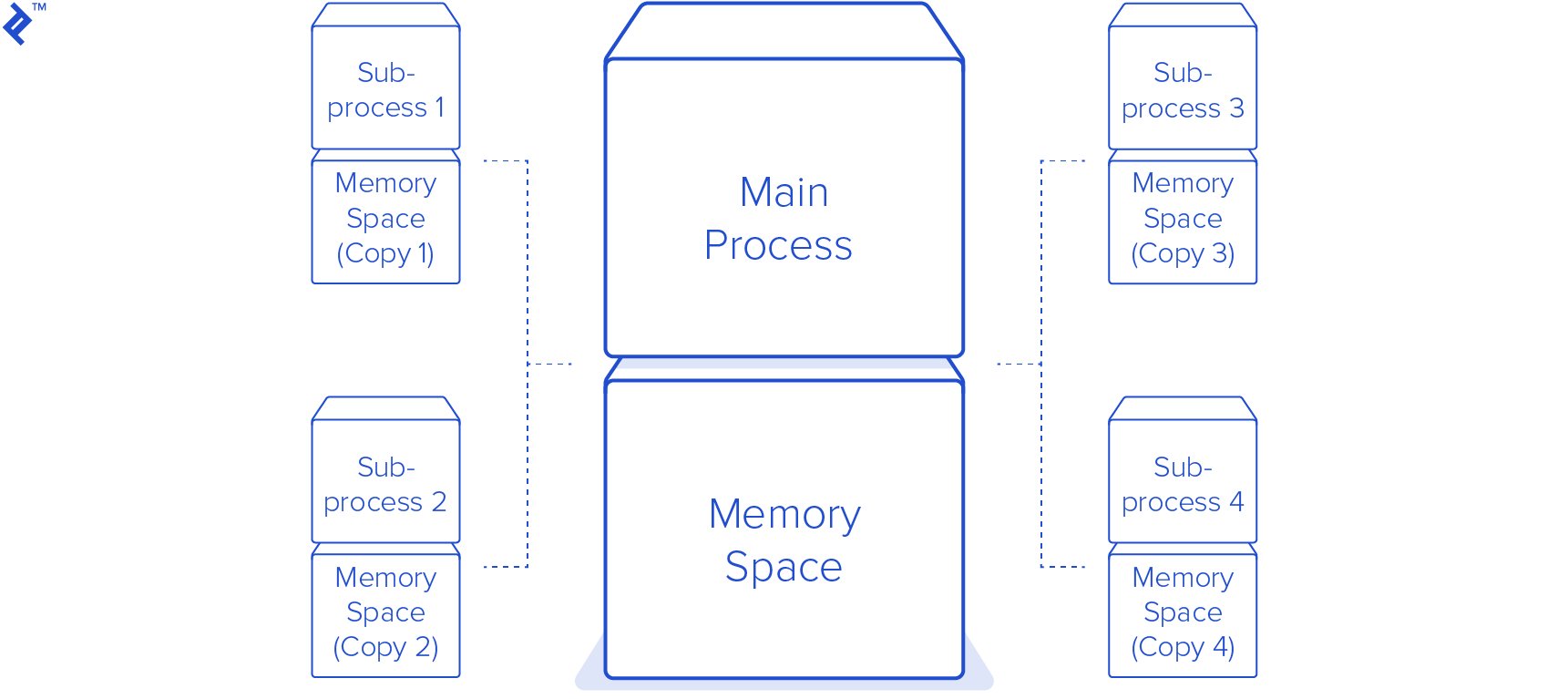 Retrieved from Toptal
Retrieved from Toptal
a. Definition
Multi-processing is partially like multi-threading, but it creates new processes instead of new threads, these processes run in parallel and are not managed by GIL. By not being controlled by GIL, all CPU cores will be fully utilized at the same time. Multi-processing is suitable in running CPU bound tasks (adding, substracting, multiplying, and dividing,…) due to the availability of CPU cores. One process will have its memory space. It means data from one process cannot be shared to another one.
Personal experience: A few months ago, I implemented a caching library for a service in my company. Unfortunately, the cache object could not be shared across processes, that problem happened due to Gunicorn run 4 Django processes on the Dev server. So I had to find another library to store cached data in disk. This is a painful and memorable experience to me.
b. How to use?
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
from multiprocessing import Process
def main():
start_time = time.time()
processes = []
for _ in range(5):
process = Process(target=do_heavy_computational_task)
process.start()
processes.append(process)
print("Done creating processes: %.2fs" % (time.time() - start_time))
for process in processes:
process.join()
print("Total time: %.2fs" % (time.time() - start_time))
c. Advantages
- Racing conditions will not happen in multiprocessing.
- Multiple CPU cores can be fully utilized.
- Use physical resource more efficiently.
- Improve system performance.
- Write code in a more structured way.
d. Disadvantages
- Memory of each process is separated from another, it cannot be shared.
- A process takes a longer time to initialize than a thread.
- Difficult to debug.
- Too many processes can result in severely degraded performance.