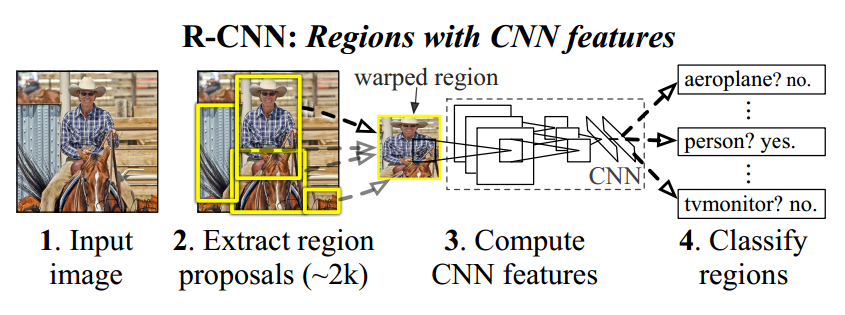
Khi tìm hiểu về topic Object Detection, ngoài các model phổ biến và được ứng dụng thực tế hiện nay như YOLO, EfficientDet, …, chúng ta còn có các model họ RCNN (region-based CNN) với accuracy khá cao. Region-based Convolutional Neural Network (RCNN) là tổ tiên đầu tiên của họ RCNN.
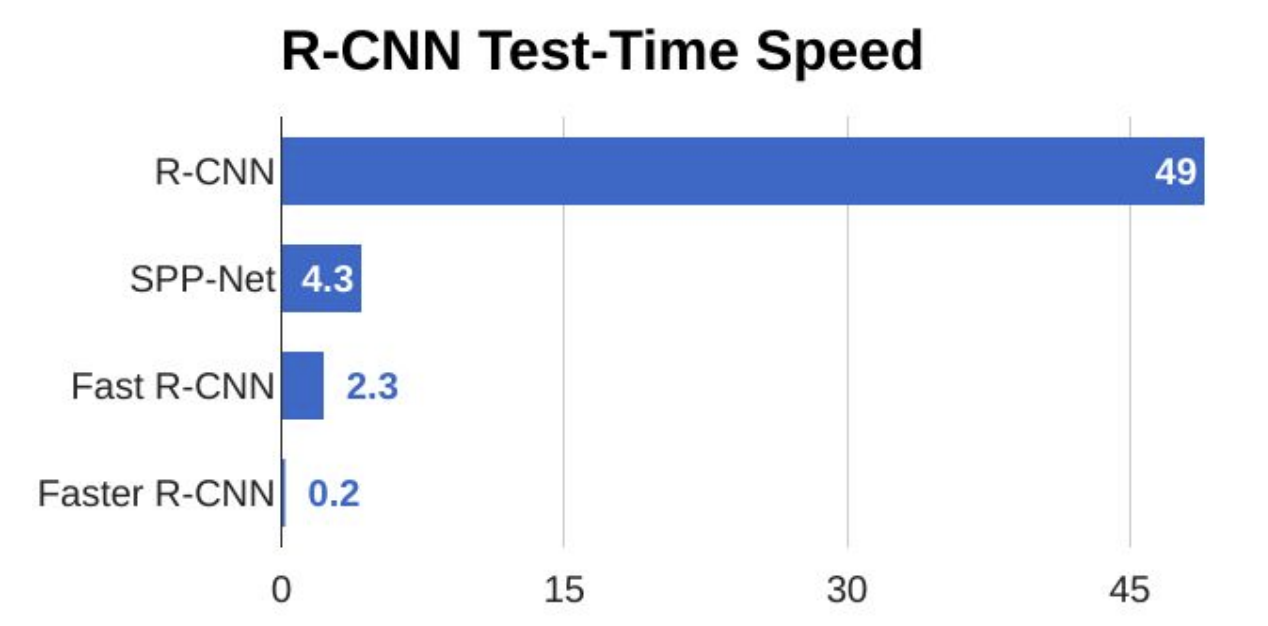
Mặc dù hiệu suất rất thấp trong thời điểm hiện tại khi so sánh với các State-of-the-art network (như hình dưới), RCNN là network đầu tiên giải quyết được rất nhiều vấn đề mà Object Detection trong quá khứ mắc phải. Trong bài viết này, tôi sẽ tổng hợp lại các vấn đề trong quá khứ và kiến thức về network này.
Các vấn đề của Object Detection
- Định vị đối tượng trong image bằng neural network
- Lượng dữ liệu được đánh label hạn chế
Cách tiếp cận của RCNN
RCNN sẽ thực hiện tuần tự theo các bước sau:
- Trích xuất 2000 vùng từ ảnh từ ảnh bằng thuật toán Selective Search
- Tính toán vector thuộc tính của mỗi vùng sử dụng Convolutional Neural Network (CNN)
- Phân loại từng vùng bằng Support Vector Machine (SVM)
Trích xuất vùng ảnh
Các nội dung bên dưới được tham khảo từ [1]
Sliding window
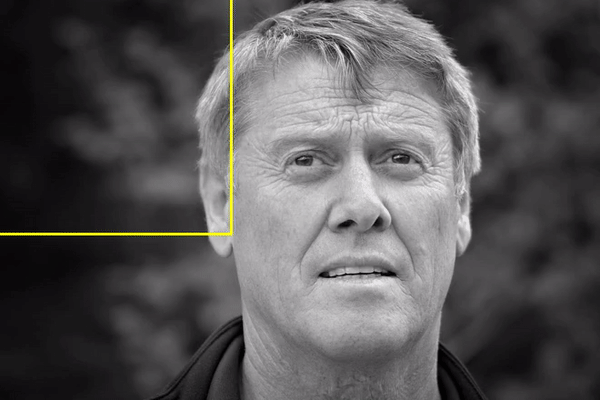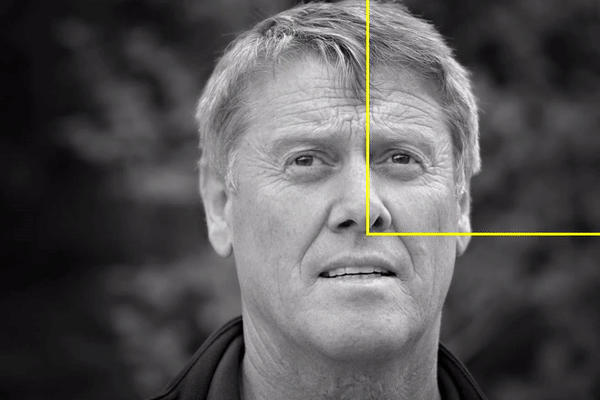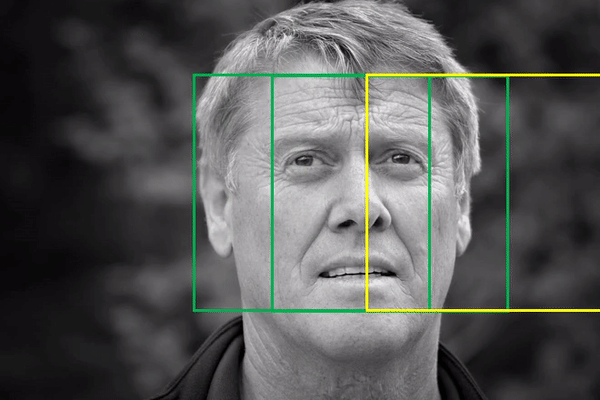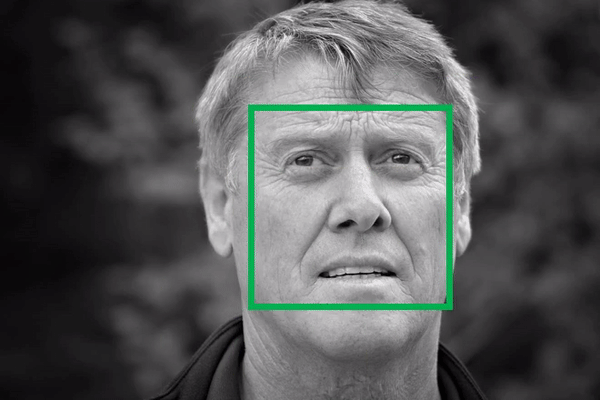
Bạn hẳn đã nghe đến việc sử dụng phương pháp Sliding Window để phát hiện đối tượng trong một ảnh (hình dưới), tuy nhiên thì đây không phải là cách tiếp cận tốt cho Object Detection, nhất là với các đối tượng có kích thước đa dạng. Nếu chỉ nhận diện những đối tượng có hình dáng tương tự nhau thì hiệu suất sẽ khả quan, ví dụ để nhận diện người đi bộ thì chỉ cần quy định kích thước window là hình chữ nhật đứng. Nhưng nếu có nhiều đối tượng với các kích thước khác nhau, chúng ta cần phải scale window ở thành kích cỡ khác nhau và cho nó trượt khắp ảnh. Cách làm này sẽ tạo ra rất nhiều phần ảnh cần phải xử lý (hơn cả 2000).
Thuật toán region proposal
Thay vì sử dụng Sliding Window, các vấn đề này có thể được giải quyết khi sử dụng các thuật toán Region Proposal. Thuật toán nhận một ảnh là đầu vào và cho ra những vùng trong ảnh, kết quả những đối tượng trong ảnh sẽ được nhận diện với bounding box chính xác (so với ground truth). Tuy nhiên, thuật toán này vẫn có độ nhiễu và sai lệch đáng kể, do đó nhiều vùng sẽ không chứa đối tượng nào hoặc vùng đề xuất quá to hay nhỏ so với đối tượng.
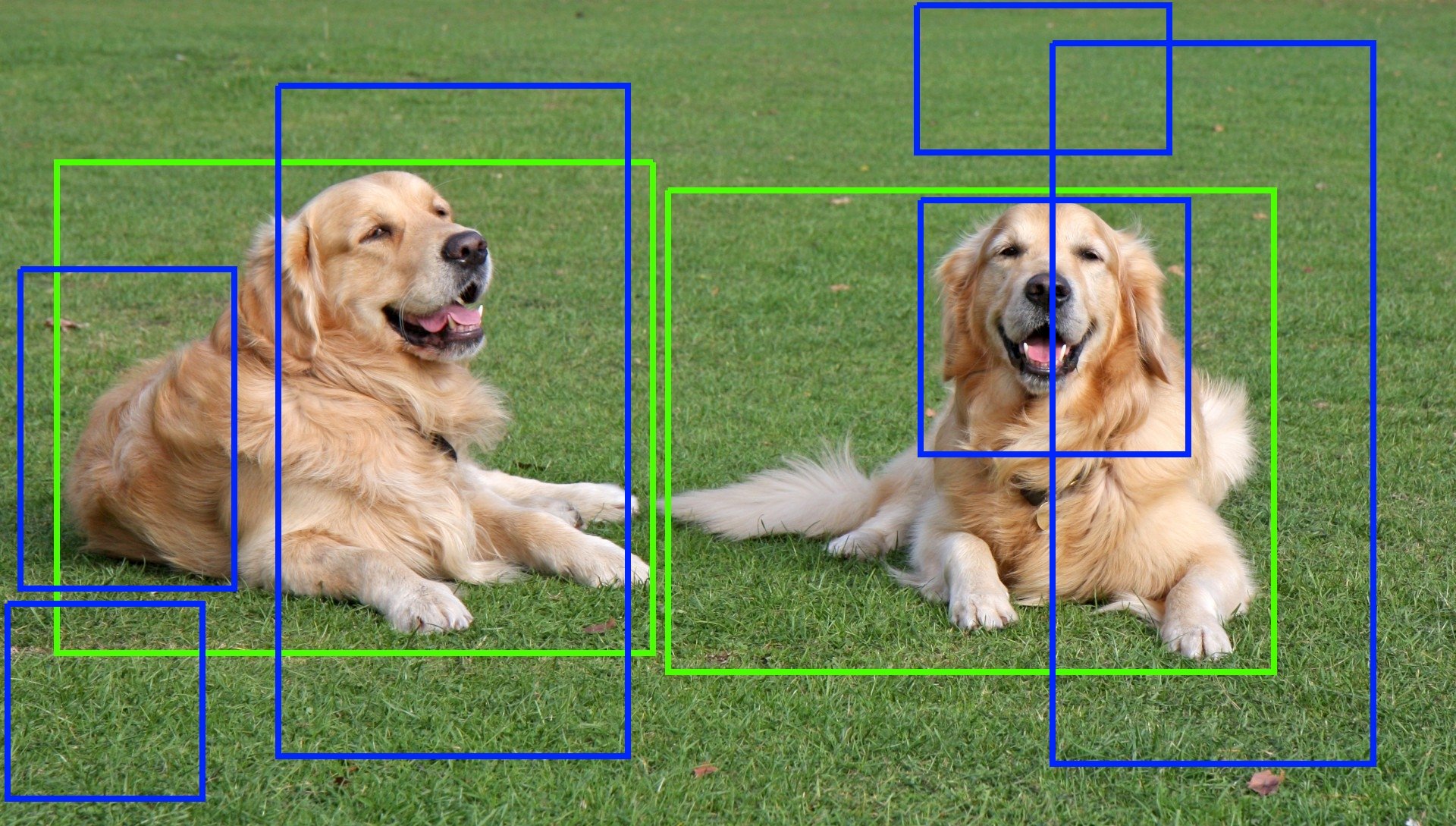
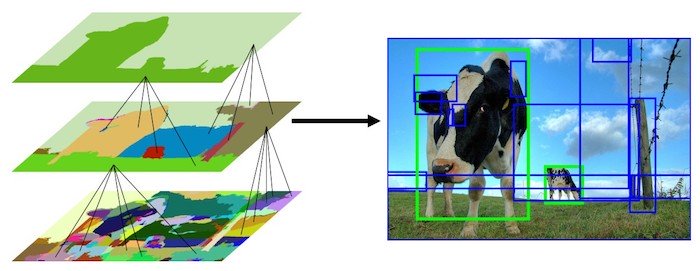
Thuật toán Region Proposal xác định đối tượng tiềm năng bằng segmentation. Một cách máy móc, chúng ta sẽ nhóm các pixel liền kề nhau lại dựa trên các tiêu chí như màu sắc, kết cấu, kích thước, …. Cách này sẽ làm giảm rõ rệt số lượng các vùng được đưa vào CNN so với Sliding Window. Một thuộc tính quan trọng của phương pháp Region Proposal là có recall cao, chúng ta sẽ giảm được Type II error (hình dưới), mặc dù Type I error khá cao.

Selective Search
Selective Search là một trong những thuật toán của Region Proposal, nó đạt được độ chính xác cao nhờ segment các đối tượng theo thứ bậc (hierarchical segmentation). Các bước thực hiện như sau:
- Sử dụng phương thức graph-based segmentation cho ảnh
- Thêm bounding box tương ứng với các phần được chia ra thành một list các vùng
- Nhóm các phần liền kề dựa trên các thành phần (Màu sắc, kết cấu, kích thước, hình dạng,…)
- Quay lại step 2
Để hiểu rõ hơn, bạn có thể xem thêm tại [1]
Convolutional Neural Network (CNN)
Trong paper của RCNN, các tác giả đã thay đổi kích thước của mỗi vùng thành 227x227 (bạn có thể chèn thêm một số thao tác biến đổi hình ảnh ở bước này). Sau đó được đưa vào AlexNet để trích xuất 4096 đặc trưng của mỗi vùng.
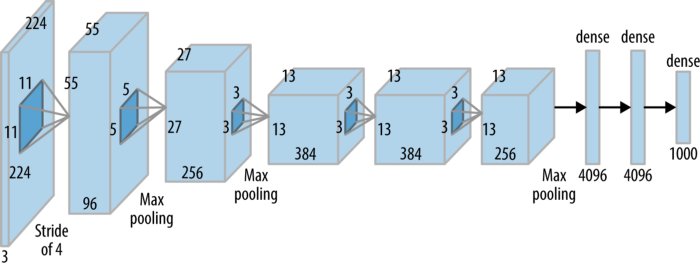
Tuy nhiên thì bạn vẫn có thể sử dụng các kiến trúc khác thay vì AlexNet, nhưng đừng quên rằng vào năm 2014, AlexNet vẫn là một SOTA CNN lúc đó đấy.
Nếu bạn thắc mắc RCNN này được huấn luyện như thế nào, thì mỗi model phải được huấn luyện độc lập, bao gồm CNN và SVM. Riêng về model CNN, chúng ta chỉ cần huấn luyện AlexNet cho một nhiệm vụ phân loại bằng một tập dữ liệu liên quan đến các đối tượng bạn quan tâm (có thể lấy từ ImageNet hoặc các tập dữ liệu mở), sau đó chúng ta sẽ bỏ Softmax layer cuối cùng.
Support Vector Machine (SVM)
Bây giờ, chúng ta đã có các đặc trưng được trích xuất, SVM sẽ được dùng để xác định lớp của đối tượng. Ứng với mỗi lớp, chúng ta sẽ có một SVM để kiểm tra có phải đối tượng thuộc lớp này hay không. Do đó, với 4096 đặc trưng, chúng ta sẽ cho vào n SVM để xác định kết quả cho từng lớp, với n là số lượng các lớp đối tượng mà ta cần phát hiện.
Về việc huấn luyện n model SVM, chúng ta sẽ dùng CNN như một provider để cung cấp input cần thiết, trong trường hợp này là 4096 đặc trưng. Khi huấn luyện thì chúng ta đã có ground truth, ta chỉ cần dựa vào ground truth của từng đối tượng để huấn luyện các model SVM cho phù hợp.
Kết luận
Thông qua bài viết này, tôi muốn được tổng hợp lại các khái niệm liên quan đến RCNN, các thuật toán liên quan đến định vị đối tượng cũng như cách hoạt động của network này. Vẫn còn một phần nữa mà tôi chưa đề cập đến đó là Bounding box regression, tôi xin phép được bổ sung trong thời gian tiếp theo.
Cảm ơn các bạn đã đọc bài viết này và hãy tiếp tục nghiên cứu nhé :D.
Tài liệu
[1] Selective Search for Object Detection
[3] R-CNN, Fast R-CNN, Faster R-CNN, YOLO — Object Detection Algorithms
[4] Rich feature hierarchies for accurate object detection and semantic segmentation